
There is some yealink phones with BLF led feature, but led lights working wrong, the lights changing (red on the call, green on idle) with big delays ~3-10 min!!, or not working at all. Calls is working great, and in FPBX "active calls" updateing great without any dealys. What can I check/change/add to make this work correctly?
SOLVED BLF led lights
- Thread starter albert-g
- Start date
-
- Tags
- blf yealink blf
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
- Status
- Not open for further replies.
The first thing I would do to diagnose this would be to get a packet capture both on the network the PBX server is connected to and the network the phone is connected to (you can do small captures on Yealink phones form the Settings->configuration page).
My guess would be that the notification messages that the phone uses to update the BLF are going missing OR if you are using UDP the NOTIFY messages may be exceeding the MTU (fragmentation), this can easily happen when there are many BLFs (many subscritions) to update on a single phone, this is especially noticable when the BLFs are monitoring a number of phones that are all in the same ring group.
My guess would be that the notification messages that the phone uses to update the BLF are going missing OR if you are using UDP the NOTIFY messages may be exceeding the MTU (fragmentation), this can easily happen when there are many BLFs (many subscritions) to update on a single phone, this is especially noticable when the BLFs are monitoring a number of phones that are all in the same ring group.
Thanks Adrian, the extensions about 10, and in one RG there is 4-8 ext., this can be many or far from many?
Also one thing that I noted and maybe its important, when I unregistering device from FPBX (and yealink going to reboot), after booting about 30min or so, the BLF LED working great without a second of delay.
P.S. On devices page I remained all by default, so for transport protocol it is set TCP

Also one thing that I noted and maybe its important, when I unregistering device from FPBX (and yealink going to reboot), after booting about 30min or so, the BLF LED working great without a second of delay.
P.S. On devices page I remained all by default, so for transport protocol it is set TCP
Last edited:
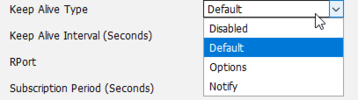
I changed TCP to UDP, and also try to change "Keep Alive Type" to "Default" on Yealnik (by default it was on "Notify").

But nothing helped, time by time lights is working good (it can be, or after phone reboot, or by itself), to me it looks like when phone registering for a while at first, it works fine, and when phone is idle for some time, the lights stop working. I will share some things from sngrep, not sure is it normal or should be different. There is many notify messages. Please advise.

Notify messages all like this.

But nothing helped, time by time lights is working good (it can be, or after phone reboot, or by itself), to me it looks like when phone registering for a while at first, it works fine, and when phone is idle for some time, the lights stop working. I will share some things from sngrep, not sure is it normal or should be different. There is many notify messages. Please advise.
Notify messages all like this.
Attachments
Hi Albert,
So we can see that for this packet MTU and fragmentation should not be the issue because we can see the Content-Length header is 549, also and dependent on where the packet was captured (in your case the server so not relavent for this diagnostic) we can also see the closing </dialog-info> tag of the XML.
Normally we would see a 200 OK response to the NOTIFIY message, we are not seeing this but instead many re-tries. This is often symptomatic of a router having closed the NAT hole first opened by the initial REGISTER packet.
You are right to look at Keep-Alives, the default in most rouers for UDP is to keep the NAT hole open for 180 seconds, but I have seen routers where this is set as low as 20 seconds. Your keep alive interval needs to be lower than the expiry time of the NAT hole. A keep alive type of NOTFIY is fine, try setting the interval lower and see if it solves your problem.
Adrian.
So we can see that for this packet MTU and fragmentation should not be the issue because we can see the Content-Length header is 549, also and dependent on where the packet was captured (in your case the server so not relavent for this diagnostic) we can also see the closing </dialog-info> tag of the XML.
Normally we would see a 200 OK response to the NOTIFIY message, we are not seeing this but instead many re-tries. This is often symptomatic of a router having closed the NAT hole first opened by the initial REGISTER packet.
You are right to look at Keep-Alives, the default in most rouers for UDP is to keep the NAT hole open for 180 seconds, but I have seen routers where this is set as low as 20 seconds. Your keep alive interval needs to be lower than the expiry time of the NAT hole. A keep alive type of NOTFIY is fine, try setting the interval lower and see if it solves your problem.
Adrian.
What it is actually called can very from router to router depending on the manufactures terminology. Generally is is referred to as "NAT Session Timeout Settings". How one sets it also varies tremendously from router to router, for example on a Draytek it can not be set in the GUI, it must be done at the command prompt with something like "portmaptime -u 300" this would set the UDP timeout to 300 seconds. In some versions of Sonicwall it is found under Firewall-Advanced on other versions it is found under Firewall->Flood Protection and is called "Default UDP Connection Timeout".
So what it is actually called and what you need to do to change it really does depend on the router your customer is using.
So what it is actually called and what you need to do to change it really does depend on the router your customer is using.
Hi Albert,
So we can see that for this packet MTU and fragmentation should not be the issue because we can see the Content-Length header is 549, also and dependent on where the packet was captured (in your case the server so not relavent for this diagnostic) we can also see the closing </dialog-info> tag of the XML.
Normally we would see a 200 OK response to the NOTIFIY message, we are not seeing this but instead many re-tries. This is often symptomatic of a router having closed the NAT hole first opened by the initial REGISTER packet.
You are right to look at Keep-Alives, the default in most rouers for UDP is to keep the NAT hole open for 180 seconds, but I have seen routers where this is set as low as 20 seconds. Your keep alive interval needs to be lower than the expiry time of the NAT hole. A keep alive type of NOTFIY is fine, try setting the interval lower and see if it solves your problem.
Adrian.
Very strange, I set all "keep alive intervals" to 15, and when I provisioned all phones again, the first ~1 hour, all is working good, In SNGREP I could see NOTIFY->OK messages, but then the same problem, as I had before. On the below screenshot I am calling from extension 39 ->41, and please note the last column, the NOTIFY messages constantly increasing (since there is no OK reply)

P.S. I checked on my firewall this UDP sessions timeouts, which was set to 1800s.
Difficult to diagnose further without a proper packet capture, screenshots of sngrep are of limited use.
You may have a NAT detection /Traversal issue. Why does the INVITE go to 41@1 something when 41 is actually 41@v something? Are 20,22,21,1,10, and 23 all on the same public IP address? If they are, they can't be all using port 5060 unless they are on the same phone or something like a multi line analogue adapter.
Is this a new installation? Is this a customers router? I ask because not all NATs are the same, some cause real problems. Also are there any SIP ALGs enabled on the router, these also cause problems more often that not.
PM me with a download link if you want to send me a full packet capture.
You may have a NAT detection /Traversal issue. Why does the INVITE go to 41@1 something when 41 is actually 41@v something? Are 20,22,21,1,10, and 23 all on the same public IP address? If they are, they can't be all using port 5060 unless they are on the same phone or something like a multi line analogue adapter.
Is this a new installation? Is this a customers router? I ask because not all NATs are the same, some cause real problems. Also are there any SIP ALGs enabled on the router, these also cause problems more often that not.
PM me with a download link if you want to send me a full packet capture.

Note for beginners:
With Adrians help, we figured out the problem, it was related to internal SIP profile values (ext_sip_ip, ext_rtp_ip), which cause some conflict with notify messages. If your PBX located inside and not public, don't set public IP address on internal SIP profile.
With Adrians help, we figured out the problem, it was related to internal SIP profile values (ext_sip_ip, ext_rtp_ip), which cause some conflict with notify messages. If your PBX located inside and not public, don't set public IP address on internal SIP profile.
I am using a on-site PBX in my SOHO setup with both internal and external IPs set on the internal IPv4 profile as I am using an external SIP client on my mobile phone and notifications work fine.
It looks like Freeswitch/FusionPBX is not recognizing your local network correctly. Check the "apply-nat-acl" setting for your profile. Default value is "nat.auto" which does not work well in some setups.
I set up a custom access control (localnet-ipv4) in Advanced -> Access Controles with default setting of "deny" and "allow" for my CIDR and then set that as the value for "apply-nat-.acl" in the profile.
Disabling "agressive-nat-detection" on the SIP profile might help as well.
https://freeswitch.org/confluence/pages/viewpage.action?pageId=3965687 gives a nice overview of ACLs in Freeswitch.
It looks like Freeswitch/FusionPBX is not recognizing your local network correctly. Check the "apply-nat-acl" setting for your profile. Default value is "nat.auto" which does not work well in some setups.
I set up a custom access control (localnet-ipv4) in Advanced -> Access Controles with default setting of "deny" and "allow" for my CIDR and then set that as the value for "apply-nat-.acl" in the profile.
Disabling "agressive-nat-detection" on the SIP profile might help as well.
https://freeswitch.org/confluence/pages/viewpage.action?pageId=3965687 gives a nice overview of ACLs in Freeswitch.
Note for beginners:
With Adrians help, we figured out the problem, it was related to internal SIP profile values (ext_sip_ip, ext_rtp_ip), which cause some conflict with notify messages. If your PBX located inside and not public, don't set public IP address on internal SIP profile.
thanks for this, so I saw the same error but did not track it down to this
I have my fusion in AWS and typically I've set both the internal and external profiles to the external IP of fusion. looking now my handsets in registration show profile internal. never been an issue until the call flow BLF issue. so what should internal be set to? the default is $${external_rtp_ip} and $${external_sip_ip} I believe, or should this be your internal IP ?
all my handsets are remote, so nothing is inside the same network as fusion
Attachments
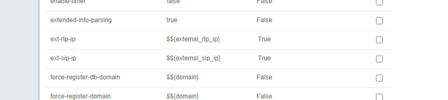
For the internal profile, ext_sip_ip, ext_rtp_ip should be set to whatever IP address you expect your phones will see packets coming from. Normally the defaults are fine. The situation that I addressed for Albert-g was more complicated than usual because three IP address ranges, internal, external, and VPN address ranges we in play.
Just for the avoidance of doubt, the issue had nothing to do with ACLs or NAT detection.
Just for the avoidance of doubt, the issue had nothing to do with ACLs or NAT detection.
- Status
- Not open for further replies.